
Northwind Traders - Spark Internals
Case Study
About
This case study Northwind Traders explains how Apache Spark works in a distributed environment compared to traditional single-node tools. Using PySpark on sales dataset, it demonstrates key behaviors such as lazy execution, parallel processing, and partitioned data writes. The examples show why Spark delays computation until an action is triggered, why some errors do not appear during transformations, and why output is generated as multiple files. The study helps build a clear understanding of Spark’s execution model for anyone moving from Excel-based workflows to scalable data engineering.
Narrow Transformations
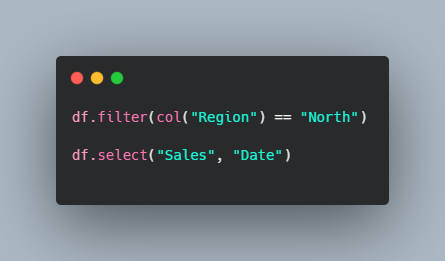
These operations apply row and column filtering on the dataset. Spark processes each partition independently, without moving data across the cluster.
-
The filter condition keeps only rows where the region is North.
-
The select statement picks only the required columns for further processing.
Because no data is shuffled between partitions, these operations are Narrow transformations. They are fast, memory-efficient, and allow Spark to build an execution plan without immediately scanning the full dataset.
Wide Transformations

These operations require Spark to move data across partitions to produce correct results.
-
groupBy("Region").count() collects rows with the same region together to calculate counts.
-
orderBy("Sales") sorts data across the entire dataset, not just within each partition.
-
repartition(100) redistributes the data into 100 partitions to increase parallelism.
All three are Wide transformations because they trigger a data shuffle across the cluster. This makes them more expensive than narrow operations, but necessary for aggregation, sorting, and controlling how data is distributed.
Lazy Evaluation

This code converts the values in the Region column to uppercase. The operation defines what needs to be done, but it does not process any data immediately.
Spark treats this as a lazy transformation. The execution is delayed until an action such as show(), count(), or write() is called. Until then, Spark only builds an execution plan and no data is read or modified
Parallelism
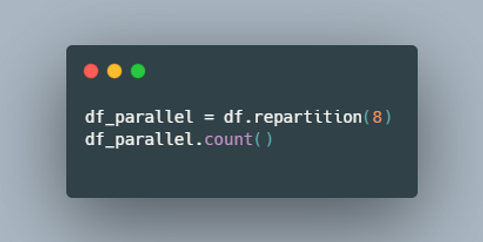
This code increases the number of partitions so Spark can process data in parallel across multiple executors.
-
repartition(8) splits the data into 8 partitions.
-
Each partition can be processed at the same time on different cores.
-
The count() action triggers execution and runs the job in parallel.
Parallelism allows Spark to handle large datasets faster by dividing work across the cluster instead of processing data on a single machine.

